问题
写了一个pyspark的代码,自定义了一些py文件import进来使用,并且通过shell脚本传8个参数,如下:
1 | !/usr/bin/env bash |
但是由--deploy-mode client切换成--deploy-mode cluster之后console上却报如下错误:
1 | Exception in thread "main" org.apache.spark.SparkException: Application application_1539260237589_6351494 finished with failed status |
信息量极少,无法判断和定位问题,通过网上搜索也无法找到答案。
问题定位
很显然,要想定位问题就必须得找到相关的详细日志。我首先想到的就是通过spark 的web UI的查找历史日志,但是通过spark application Id找不到,然后想通过yarn logs -applicationId id拉取日志但是报Log aggregation has not completed or is not enabled.。
后来看了一下运维给的技术文档,说是还有一种方法是需要到Hadoop集群的RM(ResourceManager)节点上查看日志。进入RM的管理页面,搜索对应的的application id,然后点击进入。通过顶部的日志看到:
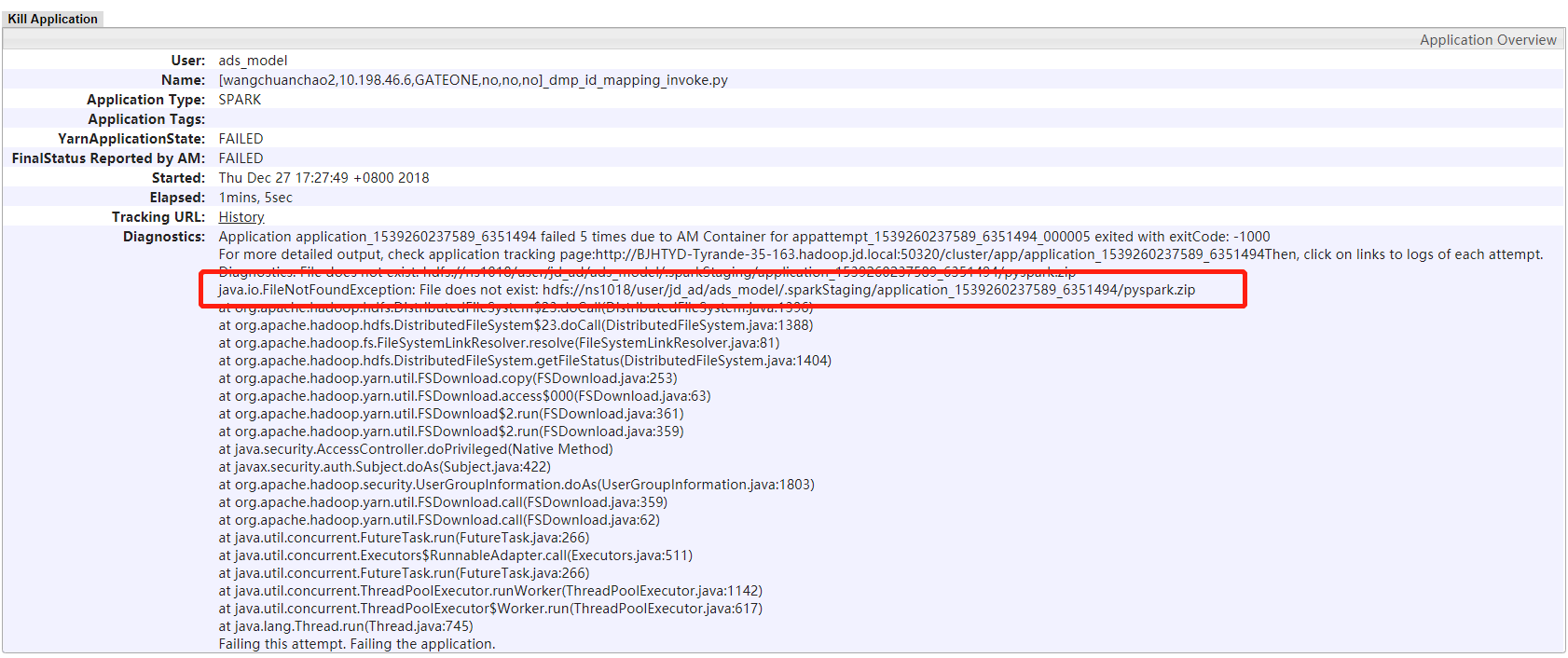
但是注意:java.io.FileNotFoundException: File does not exist: hdfs://ns1018/user/jd_ad/ads_model/.sparkStaging/application_1539260237589_6351494/pyspark.zip不是根本原因。根本原因的从底部的Logs链接中看:

点进去之后不仅spark_stderr要看,spark_stdout日志也要看, 在spark_stdout日志中看到如下错误:
1 | Traceback (most recent call last): |
所以问题是切换成cluster模式之后就找不到相应的文件了。
解决问题
找到问题,就容易解决问题,在pyspark中可通过--py-files dependencies.zip的方式引入需要import的py文件。需要需要import的py文件都达在dependencies.zip里面。配置如下:
1 | !/usr/bin/env bash |
如何还是不能运行成功,应该是代码中import时相关文件的路径涉及不对,排查思路如上,直到问题解决。